神経計算論・工学応用研究グループ > 主要業績4
 4.マッチング行動のメカニズム
4.マッチング行動のメカニズム
〜行動レベルの現象を計算アルゴリズムとして理解する〜
人間や動物は、自分の行動を選択しなければならない状況に直面します。しばしば、状況の把握に必要な情報やその行動の結果が、曖昧な場合にも、何らかの決断をしなければなりません。ある決断をするために、脳は外界から与えられた情報の断片や、似た状況に置かれた過去の経験、可能な選択肢、そしてその選択の見返りを考慮しなければなりません。
動物がどのように決断し行動するかということを調べるために様々な実験が行われてきました。典型的な例は、動物が報酬を得るためには、許された行動の中から一つを選択しなければならないような課題が挙げられます。このような課題では、十分時間が経過すると、動物はマッチング法則と呼ばれる行動上の法則を示すことが知られています(Herrnstein 1961)。マッチング法則とは、十分長い一定期間に、各選択肢を選択した回数の割合が、その選択肢から得た累積報酬量の割合に一致する、という法則です。
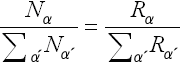 ここで、Na は、選択肢 a を選択した回数を表し、Raは選択肢 a から得た累積報酬量を表します。動物の選択に対して報酬を与える確率法則によっては、マッチング法則を満たすマッチング行動が、獲得報酬を最大にする最適行動とはならない場合も考えられます。このような場合にも、動物は最適行動ではなく、マッチング行動を示すことが知られています(Herrnstein and Heyman 1979; Mazur1981; Vaughan 1981)。マッチング行動を実現するように設計された意思決定メカニズムはいくつか提案されていますが (Vaughan 1981; Sugrue et al. 2003; Seung 2003)、なぜ動物が獲得報酬を最大にできないにも関わらず、マッチング行動を示すのか、わからないままでした。
ここで、Na は、選択肢 a を選択した回数を表し、Raは選択肢 a から得た累積報酬量を表します。動物の選択に対して報酬を与える確率法則によっては、マッチング法則を満たすマッチング行動が、獲得報酬を最大にする最適行動とはならない場合も考えられます。このような場合にも、動物は最適行動ではなく、マッチング行動を示すことが知られています(Herrnstein and Heyman 1979; Mazur1981; Vaughan 1981)。マッチング行動を実現するように設計された意思決定メカニズムはいくつか提案されていますが (Vaughan 1981; Sugrue et al. 2003; Seung 2003)、なぜ動物が獲得報酬を最大にできないにも関わらず、マッチング行動を示すのか、わからないままでした。
我々は、いくつかのよく知られた強化学習アルゴリズムも、マッチング行動を示すことを証明し、マッチング行動を示すような学習アルゴリズムに共通の性質を見出しました。この性質を解釈すると、意思決定に用いている情報が報酬期待値を予測するのに十分な情報であるときに効率的に報酬最大化をするようなアルゴリズムを用いると、実際その情報が不十分なときに報酬最大化できずにマッチング行動に至ってしまう、ということがわかりました。つまり、十分な情報が得られているときにはうまく働くが、十分な情報が得られていないときにはうまく働かないようなアルゴリズムが神経系に実装されているのではないか、という可能性を示唆しています。
この原則に当てはまるアルゴリズムは、報酬期待値の推定の仕方や行動選択確率の表し方によって、様々な実装の仕方があり、いくつかの強化学習アルゴリズムを含め、マッチング行動を獲得するようにデザインされたいくつかの意思決定メカニズム(Vaughan 1981;Sugrue et al. 2003; Seung 2003) も、この形式で表すことができます。
ある4つの学習アルゴリズムが、マッチング法則を満たす選択確率が最適選択確率とならないような2種類の課題をそれぞれ2ブロックずつ、計4ブロックを続けて学習していったときのシミュレーション結果を図に示しました。どのブロックでも最適選択確率(水平実線)ではなく、マッチング選択確率(水平破線)に近づいていくことがわかる。興味深いことに、次のブロックに入った後、最適選択確率の付近にいるのにも関わらず、わざわざ少ない報酬しか得られないマッチング選択確率に近づいていくことが見て取れます。
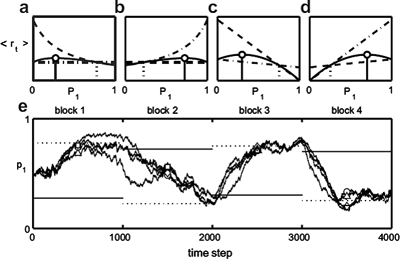
4種類の学習アルゴリズムが示すマッチング行動。Herrnstein and Heyman (1979) の課題を2ブロック、Vaughan (1981) の課題を2ブロック、計4ブロックを続けて行ったシミュレーション結果。これらの課題では、各選択に対する報酬期待値が過去の選択頻度 P1, P2=1-P1 に依存し、マッチング法則を満たす選択頻度と最適な選択頻度が異なるようにパラメータ設定できる。a-d: ブロック1〜4における各選択に対する報酬期待値(選択肢1: 破線, 選択肢2: 点破線)とトータルの報酬期待値(実線)の選択頻度依存性と、マッチング法則を満たす選択頻度(垂直破線)と最適選択頻度(垂直実線)。e: 4つの学習アルゴリズム: アクター・クリティック学習(○)、ダイレクトアクター(◇)、局所マッチング法(△)、逐次改良法(□)の選択確率の時間発展。水平実線、水平破線は、a-d の垂直実線、垂直破線に対応し、各ブロックの最適選択頻度、マッチング選択頻度を表す。
参考文献
- Herrnstein RJ (1961). J. Exp. Anal. Behav. 4:267-272.
- Herrnstein RJ (1997). The Matching Law: Papers in Psychology and Economics., Harvard Univ. Press, Cambridge, MA.
- Herrnstein RJ, Heyman GM (1979). J. Exp. Anal. Behav. 31:209-223.
- Herrnstein RJ, Vaughan WJ (1980). In Staddon, J. (ed.), Limits to action: The allocation of individual behavior. Academic Press, New York.
- Mazur J (1981). Science, 214(4522):823-825.
- Seung H (2003). Neuron, 40(6):1063-1073.
- Sugrue LP, Corrado GS, Newsome WT (2004). Science, 304:1782-1787.
- Vaughan WJ (1981). J. Exp. Anal. Behav. 36:141-149.
- 【主要業績】1.シナプス可塑性のメカニズム
- 【主要業績】2.シナプス可塑性が神経細胞の選択性や局所回路の機能に及ぼす影響
- 【主要業績】3.神経細胞の発火特性が局所回路の挙動に及ぼす影響
- 【主要業績】4.マッチング行動のメカニズム
- 研究業績リスト
- グループ研究者紹介